Stable Diffusion 核心技术解读,让你秒懂的 AI 绘图模型
虽然我很早就开始使用 Stable Diffusion了,但基本是浅尝辄止:搭建好本地环境,画了一些图片图,然后看了下 API 接口,并接入到了 GeekAI 创作助手,然后。。。就没有然后了。我平常的工作也很少用到 AI 绘图,偶然要用的话一般也用 MidJourney 解决。
上周,为了满足工作需求,我尝试用ComfyUI创建AI换装流程,并设置了本地运行环境。然而,我发现ComfyUI比之前用过的Stable Diffusion WebUI复杂。后者操作简单,只需输入提示、选模型、调参数就能生成图片。而在ComfyUI中,除了选模型,还需加载Clip模型、VAE等,这些我以前只是听说过名字而已。
由于跳过很多基础的原理性东西,以至于现在在操作上遇到很多问题。于是打算花点时间把 Stable Diffusion 的基础知识重新学习了一遍。学完之后我的感受是,基础知识远远比技巧重要,不懂原理,你学习技巧会很吃力,即使你通过大量的练习掌握了一些 AI 绘画技巧,等换一个软件,你之前学的技巧可能就不适用了。 比如,如果两个 AI 绘图软件使用的 clip 模型不一样,那么它们所用到的提示词技巧可能 就会不一样。如果你掌握了底层原理和基础知识,那么你的技能迁移也会比别人快很多。
这篇文章是我自己学习 Stable Diffusion 基础知识的时候整理的几条笔记。
# 神经网络
首先,我们一起来了解下AI模型的最底层结构单元:神经网络。
不要被技术名词吓到,你无需了解技术细节,只需关注它的思想即可。
下面这张图代表一个最简单的计算机神经网络。
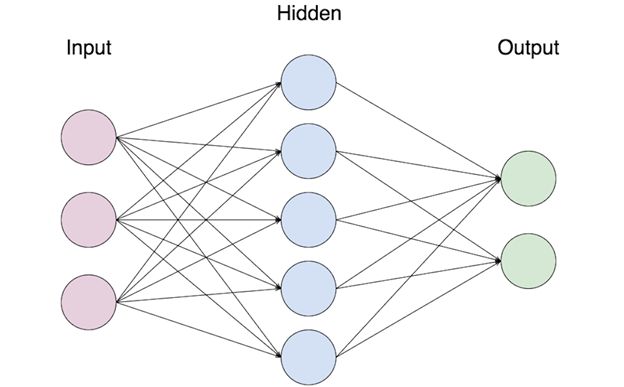
它从左到右分为三层。
第一层代表输入的数据,第二和第三层的每一个圆点代表一个神经元。
第二层叫“隐藏层”。
第三层是“输出层”。
数据输入进来,经过隐藏层各个神经元的一番处理,再把信号传递给输出层,输出层神经元再处理一番,最后作出判断。
从下面这张图,是一个图片识别的神经网络的推理过程。

输入一张图片,提取图片的特征参数,然后把这些特征参数作为神经网络的参数输入,经过一系列中间隐藏层的神经元处理,然后通过输出神经元做出判断。
# 深度神经网络
所谓“深度神经网络”顾名思义就是层次比较深的神经网络,简单来说就是中间的“隐藏层”不是一层,而是由很多个“隐藏层”组成的。
如果不明白可以看下面这张图,左边是简单神经网络,右边是深度学习神经网络。

# AI大模型
所谓 AI 大模型,其实本质上就是一个深度神经网络。只不过这个网络拥有超大规模参数,包含成千上万层神经元,具有高度复杂性。
# 大模型的两个特点
第一个特点就是...大。首先大模型拥有超大规模的参数,比如 GPT-3.5 有1750亿个参数。
其次是到模型的隐藏层有很多很多层,成千上万层。由于大模型拥有如此多的参数和隐藏层,以至于它中间的推理过程基本就是一个黑盒,你根本没法搞清楚为什么模型会输出这个结果。这个是不是跟我们人类大脑的工作机制有点类似,给你一张图片,你一眼就看出那是一张色情图片,但是你没法说出为什么它是一张色情图片,你只能说当这张图片信息进入你的大脑之后,你大脑的神经网络给出的判断就是这样子。这是一件非常有意思的事情。
大模型的另一个特点是,输出结果不稳定。我们现在已经知道,神经网络的核心功能其实就是做预测,那么既然大模型本质上就是一个神经网络,那么说明大模型唯一会的事情也是做预测。以大语言模型为例,大语言的模型的输出其实本质上有点类似文字接龙游戏,它把你的提问(prompt)作为参数输入到神经网络,然后把神经网络推理预测的下一个词输出返回给你。我们可以看下面的例子。
它的推理流程大概是这样的。
第一步,大模型把 “hello” 作为模型参数(可能要先经过一定的处理)输入到大模型神经网络,神经网络经过一系列的推理后预测下一个词 (token)是 “Hello!”
第二步,把提问和第一个结果输入模型,然后模型推理预测出第二个词是“How”
第三步,然后再把 “Hello! How” 作为参数输入模型,模型预测到下一个词是“can”
......
第N步,重复第三步,这样直到输出完整的回答。
然而,由于大模型的深度神经网络的隐藏层太多,无法确保每一个隐藏层每一次推理得到的结果都是一样的。所以每次预测的结果不一定完全一致。举个不恰当的例子,你每天上班都经过一家早餐店,早餐店的大爷跟你很熟了,你每次经过他的店门口都会跟他打招呼“早上好”,他可能大部分时候都回你一句“早上好”,但是偶尔也会直接回你一句“你吃了吗?”。
如果你还不理解,我这里举一个简单的识别手写数字的神经网络,假如这个深度神经网络的隐藏层有是几十层。下面有张图,你可以感受一下。

咱们把逻辑简化一下,信号从输入层进去,假设最终从0号输出口出来那么就是数字0,从1号口出来就是数字1。假如现在有个图片信号在经过第10层的隐藏层的时候走错了岔路,本来应该从2号输出口出来,结果从8号输出口出来,也就是把1识别成7了。
# AI绘图大模型
我们先快速了解下面几个大家常见几个技术名词。
Diffusion Model: 扩散模型,直接生成图片,需要大量的计算资源,计算速度慢。目前我们熟知的 Stable Diffusion, DALL-E, MidJourney 等都是扩散模型。Diffusion Model 不仅仅可以用来生成图片。大部分的音频,视频生成模型也是用的 Diffusion Model 技术。
Latent Diffusion Model:潜在扩散模型,Diffusion Model 改进版,增加了一个中间层,叫做潜在空间(Latent Space)。先把图片压缩,降低维度,放入潜在空间。比如把原本512x512的图片先压缩成64x64再进行计算,这样能大大减少计算量。
Stable Diffusion:稳定扩散模型,基于 Latent Diffusion 开发的。需要注意的是之所以叫做 Stable Diffusion,并不是它真的比前者稳 定,只是因为研发它的公司叫做 Stability AI,相当与品牌冠名了。
Flux:由黑森林团队(原Stability AI技术团队)研发,基于多模态和并行扩散的Transformer架构,是目前最强大的开源生图模型,官方测 试数据在各方面都优于目前最优秀的商业生图模型 MidJourney v6.0。
Stable Diffusion WebUI:基于 Stable Diffusion 开发的 Web 应用,把原本繁琐的安装配置做成容易操作的网页界面,还支持很多插件, 降低普通用户的使用门槛。SD-WebUI 是目前最受欢迎的 Stable Diffusion 应用,没有之一。
ComfyUI:另一款基于 Stable Diffusion 开发的非常强大的 Web 应用。ComfyUI 最大的特点是它通过节点流程的方式,让用户能够更加精准地定制工作流,并确保了良好的可复现性,能够实现更复杂的绘图任务。同时,ComfyUI在生成图片时进行了优化,显著提高了生成速度。并 且,ComfyUI 不仅支持 Stable Diffusion 模型,也支持 Flux 等其他 Diffusion 模型。
# Stable Diffusion 原理
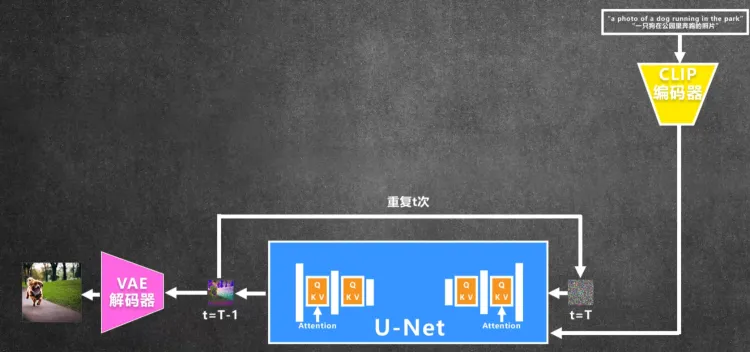
下面这张图片是 Stable Diffusion 生成的图片的简单流程。
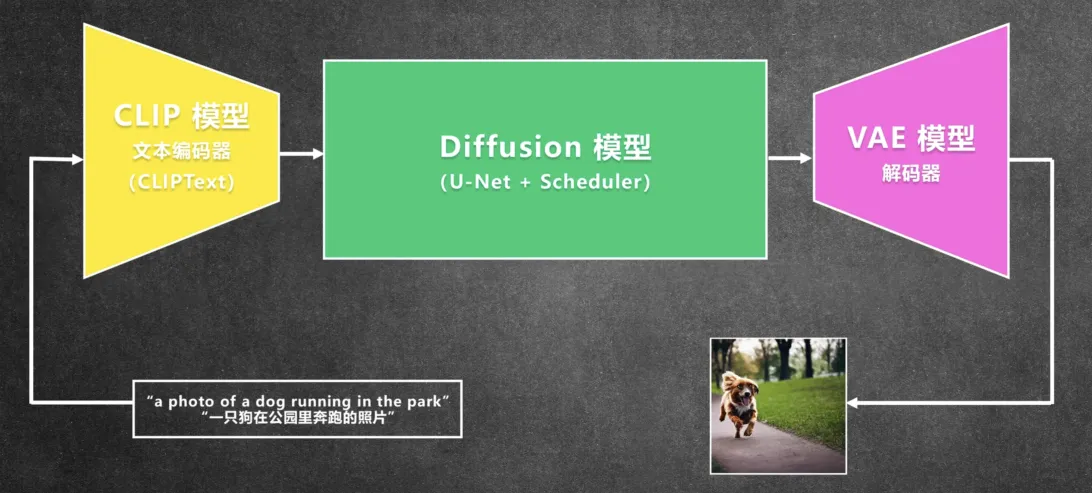
第一步,用户输入图片提示词,比如“a dog running in the park”
第二步,提示词经过文本编码器(CLIP模型)转换成向量输入到 Diffusion 模型
第三步,推理生成图片特征,这一步是在潜在空间完成的
第四步,使用图片解码器(VAE)将潜在空间的图片特征还原成图片
# Diffusion 模型原理
下面这张图展示了 Diffusion 模型训练的大概工作流程。

首先给定一张图片,然后随机添加一些噪声,重复这一动作,直到最后只剩下噪声,然后在训练一个神经网络(UNet),把噪声图片一步异步还原到原来的图像。
为什么要添加噪声而不直接移除像素?是因为移除像素会导致图片信息丢失。
那又为什么要一步一步添加噪声,而不是直接一次用噪声覆盖图片呢?因为这样能让模型更容易学习到图片的特征。通常,噪声不是平均添加到图片,因为这样太慢了。为了节省时间,一般是先少后多,前面步骤噪声少,图片的特征损失的就慢一些,后面随着噪声的占比越来,模型学习到的图片特征就越来少,所以你就可以一次添加更多的噪声,这样既能提高训练的效率,又能损失很少的图片特征。
图片的还原过程是大概是这样的:
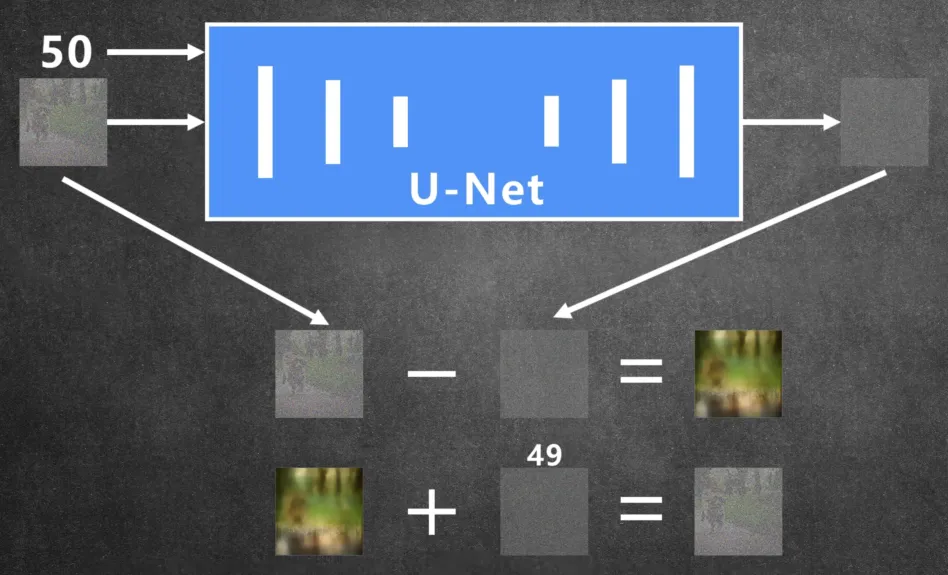
首先从训练数据中随机选中一张图片,在图片中添加一定的噪声,假设添加步数等于50的时候的噪声数量,然后把带有噪声的图片和步数50输入到 U-Net 网络,就可以预测出图片中有多少噪声,然后在把噪声图减去噪声就得到原图。
但是通常都不可能一次精准预测出噪声,最先出来的图片基本只是一个很模糊的轮廓,这时我们只需把这张生成模糊图当做原图,然后再添加49步时候的噪声数量,连同步数49一起再次传入 U-Net 网络模型再预测出噪声,然后再把那张模糊的原图减去这次预测出来的噪声,然后图 片就会更清晰一点,就这样一步一步迭代最终就能还原清晰的原图。所以我们在用 Stable Diffusion 或者 MidJourney 绘图的时候,会发现图片有个从模糊到清晰的过程。
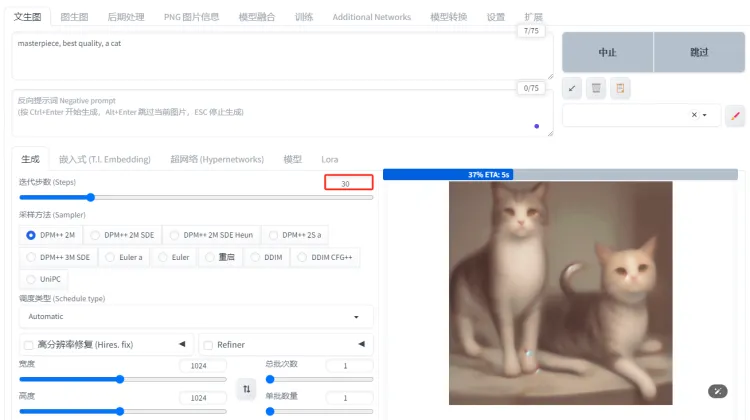
值得一提的是,其实就是 SD-WebUI 中的“迭代步数”参数就是上面添加噪声的步数,你很容易知道,步数越大,能还原的细节就越多,同时推理的时间也会越长。通常对于 Stable Diffusion 来说,20-30 的步数是个比较合适的平衡点,既能保证图像质量,又不会过度消耗时间和资源。这么说来 Flux 的 Schnell 模型可以做到4步出图,不得不说确实非常牛逼了。
接下来我们看看Stable Diffusion 的文生图是如何实现的。

大体的步骤跟上面还原图片的过程是类似的,首先是根据传入的“种子”(seed参数)生成一张随机噪声图,然后把我们的“提示词”(prompt参数)输入 CLIP 模型,转换为文本特征向量。
得到文本特征之后,将文本特征和噪声图,以及步数一起输入 U-Net 网络进行预测,然后再减去噪声,还原图像。但是这样最后得到的图像 只是有点像我们的文本输入,而不能精确展示文本所描述的内容。此时我们引入一个 “Classifier Free Guidance”(CFG参数)的方法去加强引导, 简单来说就是想办法放大文本输入的影响力。
CFG 的具体做法是,首先用 U-Net 预测两个噪声,一个是有文本输入的,一个是没有文本输入的,然后把这两个噪声相减,得到的就是在文 本引导下增量噪声,然后我们把这个增量噪声进行放大,比如放大7.5倍(通常是最优值),最终就得到一个加强了的文本引导噪声。
最后,就可以回到之前的步骤,用噪声图减去这个文本引导噪声,这里顺便提一句,如果你输入了负面提示词,那么还需要减去负面提示词的噪声,使得结果更加远离“负向提示词”的图像。 重复迭代这个步骤最终得到恢复的原图。
# CLIP 模型
CLIP 模型的全称是 Contrastive Language-Image Pre-training,主要功能就是把用户输入的提示词文本转成特征向量,便于输入到潜在空间。因为 CLIP 模型只支持英文,所以通常 AI 绘图软件的提示词也只能输入英文。一看名字就知道,CLIP是一个预训练模型,采用对比学习的方式进行预训练。它训练的数据集是图像-文本数据对,将图像和文本分别输入一个图像编码器和一个文本编码器,得到图像和文本的特征向量。然后计算两个特征的相似度。 训练好以后,来自同一个样本的特征相似度会很高,不同样本之间向量的相似度会比较低,这样就可以把文字和图片联系起来。
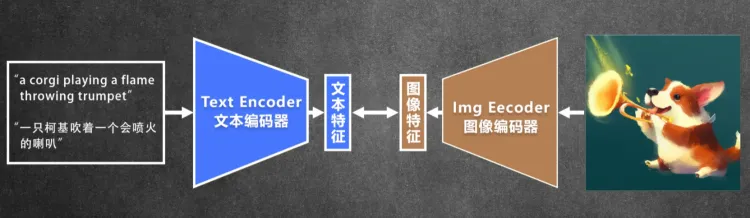
CLIP 模型有两个编码器,一个文本编码器,用文生图。还有一个图像编码器,用于图生图。
Stable Diffusion 最开始是用 OpenAI 的 CLIP 模型,该模型是用4亿图文对采用自监督学习 的方式进行训练的。值得一提的是,OpenAI 的 CLIP 模型虽然开源了,但是训练集没有开源。所以 Stable Diffusion 2 的时候把模型换成了另一完全开源的 OpenCLIP 模型。
# VAE 模型
VAE 的全称是Variational Autoencoder(变分自编码器)。它包含一个编码器和一个解码器,输入一张图片经过编码器得到潜在空间(Latent Space)里面的特征信号,然后在潜在空间里面进行计算之后再通过解码器还原成原来的图片。
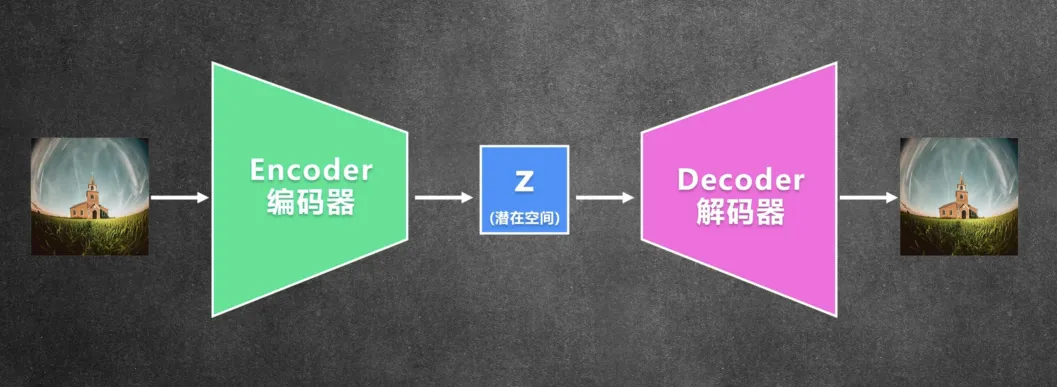
所以 Stable Diffusion 在训练模型的时候,需要先用 VAE 的编码器把图片压缩到潜在空间,然后在潜在空间里面训练扩散模型。所以扩散 模型的输入输出都是潜在空间里面的特征,而不是图片本身的像素。从上面我们介绍 Stable Diffusion 的原理的时候你应该也发现了,在生成图片推理的时候,**一开始的随机噪声也是在潜在空间里面生成的,整个计算推理也是在潜在空间里面完成的。**用VAE的好处是可以大大 减少训练和推理的时间和硬件需求,比如训练的图片是512x512的,训练的时候会压缩到64x64放入潜在空间,这样计算量会小很多。当然,这样做带来的副作用就是,经过压缩再还原的图片,会损失一些图片精度和细节。
顺带提一句,有的模型自带 VAE模型,比如 SD1.5 SDXL, 有些模型需要外挂 VAE,比如 Flux,你需要下载单独的 VAE。
最后再梳理一下整个 Stable Diffusion 的结构:
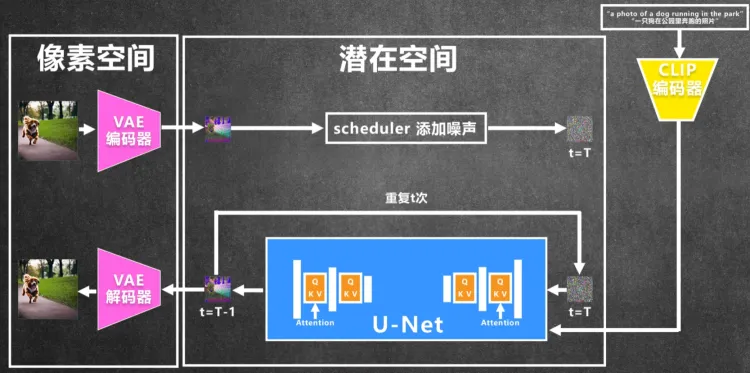
第一步,把训练过的图片经过 VAE 编码器,压缩降维到潜在空间。
第二步,根据 Scheduler 来添加噪声,之后就从噪声开始推理,把噪声和 t(步数) 都输入到 U-Net 网络进行推理,同时把文本引导经过 CLIP 编码器生成的文本特征也输入到 U-Net 网络。
第三步,U-Net 预测噪声后经过计算,得到前一步的噪声图,这样一直重复 t 步直到得到没有噪声的图像特征。
第四步,最后经过 VAE 解码器还原成像素图片。
模型训练好了之后,文生图只需要执行下半部分的反向推理就好了,随机生成噪声,加入文本引导进行推理就行。
# 微调模型
下面我们介绍一下 Stable Diffusion 几种常见的微调模型。所有的微调模型的原理都差不多,就是想办法在 U-Net 网络增加一些新的特征 信息进去。有些直接训练 U-Net 网络,有的是增加一个额外的网络来影响 U-Net 网络实现。
# Dreambooth
Dreambooth 模型是直接在 U-Net 模型上动刀,也就是直接用新的图片和关键词来调整 U-Net 网络参数。所以保存的时候需要保存整个修改 过的模型,模型文件会比较大。当然,好处是可以单独使用。
# LORA
LORA 是在 U-Net 中加一些层,然后通过去训练这些层调整 U-Net 的输出。保存的时候只需要保存额外增加的这些层,文件比较小,一般在 几十到几百MiB,所以 LORA 模型不能单独使用,比如依赖基础模型。
LORA 模型主要能够让你生成风格一致的图片,实现风格迁移。比如生成某个人物的系列写真照,就可以通过训练一个 LORA 模型来实现。
# Textual Inversion
又叫嵌入式模型,它的工作原理是通过调整 CLIP 模型使它生成具有特定属性或特征的图像。通过在提示词中输入特定的提示词可以精确控制生成图像的外观,颜色等属性。
比如你下载了一个八神童子的嵌入式模型(Yagami ),那么只需要你在提示词中输入包含了 “Yagami ”关键词,那么不管你其他提示词是什 么,输出的图像人物面部特征都是八神童子。
嵌入式模型应用的更多的是在负面提示词中,因为在 WebUl 中生成一张图像时,我们通常会输入一个负面提示词的起手式,如“低分辨率、模糊、扭曲的五官、错误的手指、多余的数字,水印”等,以避免生成低质量的图像。这时我们可以将大段的描述性提示词整合打包成一个嵌入 式模型中,那么我们只需在负面提示词输入这个嵌入式模型的名称即可产生同等甚至更好的效果。
另外,由于嵌入模型只需要保存学习到的特征,所以模型文件更小,一般只有几十KiB,是最小的微调模型了。
# ControlNet 模型
ControlNet 是通过训练另外一个神经网络去调整 U-Net 网络,本质上是通过输入一些额外的信息,以更好地“控制”扩展模型生成特定的内容,从而实现对扩散模型生图的精准控制。
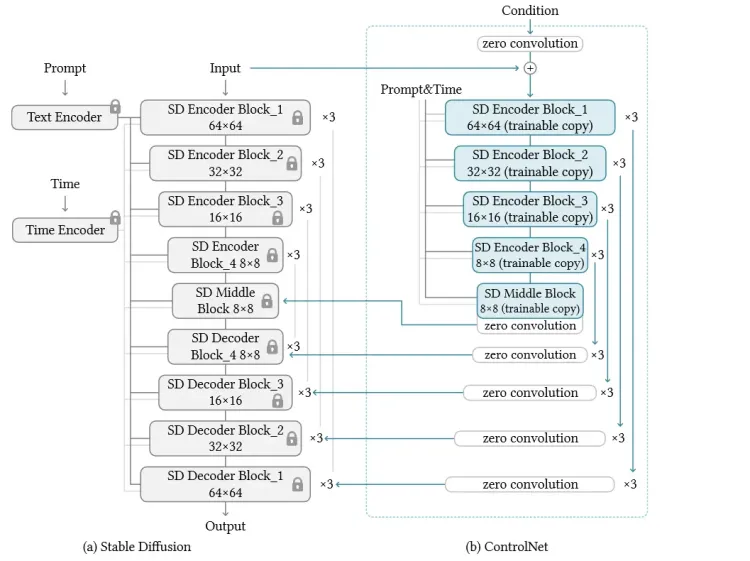
首先,你需要上传一张参考图片,然后 ControlNet 模型可以从图片中提取图片中特定的“姿势”信息。然后把这些信息输入到潜在空间 ControlNet 网络进行计算。ControlNet 会将原始网络的模型复制一份,在其上施加控制条件,最后将施加控制条件之后的结果和原来模型的结果 相加获得最终的输出。
ControlNet 模型的下载地址:https://huggingface.co/lllyasviel/sd_control_collection/tree/main (opens new window)。
看起来包含了很多模型,但是我们通常用的也就下面几大类。
# 轮廓类
轮廓类主要是通过图像的轮廓线稿和色块来控制图像。 用的比较多的是 Canny(硬边缘) 和 Lineart(线稿)模型,通常用于人物肖像绘图。其工作原理大概是这样的。

# 景深类
通过画面中物体的前后景深关系来控制图像。 常用的模型是 Depth(深度)和 NormalMap(法线贴图),通常在复刻建筑设计风格的时 候用的比较多。

# 对象类
通过人物骨架特征和面部轮廓来控制图像。 典型的模型就是大明鼎鼎的 OpenPose(姿态)了。用来控制人物造型,动作那是相当好使。

# 重绘类
直接通过参考图来重绘,没有可视化的特征提取。常用的模型有 Inpaint(局部重绘)和 Tie(分块)。

值得一提的是,我们常说的无损放大功能,也可以用 Tile(分块)模型来实现。把一张大图分块,然后分别对每个小块重绘,最后合并成一 张大图。跟直接生成大图相比,这样可以大大减少计算资源。

关于 ControlNet 模型的详细解释请参考这篇文章:14种 ControlNet 官方控图模型的使用方法 (opens new window)。
本站博文如非注明转载则均属作者原创文章,引用或转载无需申请版权或者注明出处,如需联系作者请加微信: geekmaster01