DeepSeek R1 的核心技术解读,你不能不知道的 AI 干货
杨立昆
DeepSeek-R1 的横空出世,这不是一个简单的中国 AI 技术超过美国的问题,而是开源模型超越了专有模型,这是开源世界的胜利。
DeepSeek凭借其创新的技术和卓越的性能,迅速崭露头角,成为行业内备受瞩目的力量。DeepSeek的应用不仅在国内外各大社交媒体平台上取得了显著的用户增长,还在AI技术的多项评比中名列前茅,展现了其强大的市场竞争力。 DeepSeek R1模型引入了不依赖监督微调的强化学习技术,使得模型在微调后的性能大幅提升。例如,在数学能力方面,基础模型的得分为100分,而经过微调后,得分可达到450分。本文基于对DeepSeek-V3和R1论文的研究,解析 DeepSeek-R1 的训练过程以及其核心技术原理。
# DeepSeek R1 的核心贡献
首先,我们先要搞清楚一个问题,DeepSeek-R1 之所以在全球范围内引起了如此大的震动,并不是因为 R1 模型能力的强大,因为毕竟 R1 再强大也比不过 OpenAI 的 O3 模型。 DeepSeek-R1 本次之所以破圈,我个人觉得主要有两个原因:
- DeepSeek 提供了一套高效并且低成本训练推理的模型的方法,并将这种“高效”能力复制到小模型中。用更通俗的话来说,就是 DeepSeek R1 向世界证明了,不用大量标注数据,靠AI自己“琢磨”也能变聪明,还能把这种变聪明的方法“传授”给小模型。
- DeepSeek 将整套训练方法以及全部模型开源,重塑了AI技术发展范式,降低行业门槛的同时激活全球竞争,为全球AI生态注入新活力。正如 Meta 的首席科学家杨立昆所说:“这不是一个简单的中国 AI 技术超过美国的问题,而是开源模型超越了专有模型,这是开源世界的胜利”。
# R1 推理模型解决了什么问题?
事实上,我们完全可以采用提示词工程来实现推理模型的效果。ChatGPT 刚出现的时候,很多网友就发现,在提示词中添加 “请一步一步慢慢思考”,能够提高 AI 的输出质量。后来大家还发现,在提示词中加入思维链,可以明显增强大语言模型的推理能力。而 DeepSeek R1 只是通过强化学习,把这种生成长思维链的推理能力内置到了模型的基础能力之中。简而言之,DeepSeek R1 解决了用户的两个问题。
- 不用每次都输入长长的思维链提示词引导 AI 进行推理思考。
- 降低专业领域COT(思维链)指令的编写门槛,因为不是每个人都能写出专业的 COT 指令,而 DeepSeek-R1 生成的推理过程甚至具备启发人类专家的价值。
# 什么是思维链?
思维链(Chain of Thought)其实就是引导模型一步一步推理思考得出答案,给出推理过程。
示例说明:以数学问题为例,对于一个简单的算术题 “如果一个苹果 3 元,小明买了 5 个苹果,他一共花了多少钱?”。传统的语言模型可能直试生成答案 “15 元”。而采用 COT 的模型会先输出中间步骤,比如 “每个苹果 3 元,买了 5 个,所以 3×5 = 15”。
# 哪些问题需要 COT?
- 数学
- 编程
- 复杂的决策问题,例:企业是否需要扩大生产线?
- 开放式讨论问题,例:如何提升城市空气质量?
- 需要多步骤思考的问题,例:规划一场出国旅行
# 不需要 COT 的
- 文本生成、创意写作。
- 非常简单的问题,比如2+3等于几?
- 自我认知。比如用户问:hello,你是谁?
- 翻译。
- 知识问答。比如说,中国的首都在哪?深圳有多少人口?
DeepSeek R1 收集了大约 600k 个与推理相关的训练样本(强制推理),以及大约 200k 个与推理无关的训练样本(强制不使用推理)。共800K条微调数据。除了这些 SFT 训练样本,其他问题由 AI 自己判断是否需要推理。
# 专业术语
- RL - LLM(Reinforcement Learning for large Language Model)大语言模型强化学习。
- MCTS(Monte Carlo Tree Search) 蒙特卡洛树搜索,是一种用于在决策过程中寻找最优策略的搜索算法。
- RLHF(Reinforcement Learning from Human Feedback) 基于人类反馈的强化学习
- GPQA(Graduate - Level Google - Proof Q&A Benchmark)即研究生水平的专家推理基准,是人工智能领域中一个重要的评估基准。它由 448 个困难的多项选择题构成,这些问题无法通过谷歌搜索轻松回答。其涵盖生物学、物理学和化学等多个学科领域,由各领域的主题专家精心设计。
- SFT(Supervised Fine - Tuning)监督微调。使用标记好的数据进行微调训练,目标是让已预训练模型适应特定任务或领域,主要用于 Post-Training。与之对应的Pre-Training(预训练)目标是让模型在大量未标记数据上学习通用特征,不针对特定任务。
# DeepSeek R1 训练的过程
核心思想: 在简单的奖励标准下,直接上强化学习,模型自动进化,找到最优解。
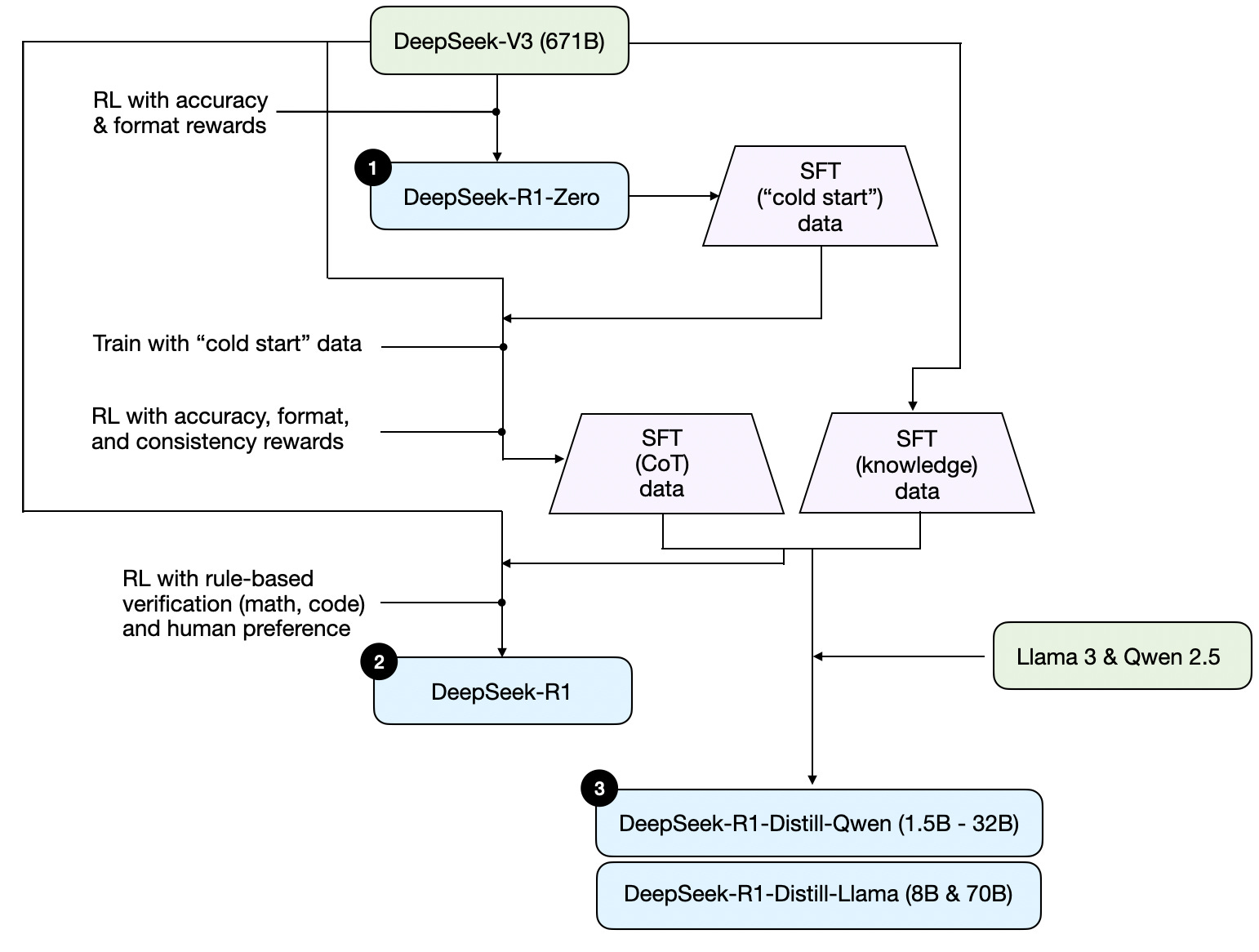
接下来我们开始一步一步拆解 DeepSeek R1 以及相关蒸馏模型的训练过程。
# DeepSeek-R1-Zero
首先,以 DeepSeek-V3 为基础模型,通过强化学习得到 DeepSeek-R1-Zero。具体步骤是,准备一些需要AI回答的问题,然后在训练时候把问题填入一个提示词模板(如下图所示)中,让 AI 按照提示词的要求去生成答案,即要求模型必须先在脑海中思考推理过程,然后把推理过程输出放在<think>标签中,并将问题答案生成放入<answer> 标签中。

# 奖励模型
在训练过程中给出一个奖励模型,用来决定强化的学习的优化方向。激励模型就两条:
- 准确性激励。这个主要针对数学问题和编程问题。因为数学题的答案我们是可以事先知道的,对与不对非常清晰;编程问题也一样,最后就看代码能不能运行,运行结果符合不符合要求,这个判断也是非常清晰的。
- 输出格式激励。主要检查两种行为,第一是看是否输出推理过程,第二看是否按照指定的格式输出了,也就是推理过程要放在
<think>, 答案要放在<answer>。
总结来说,DeepSeek-R1-Zero 的训练方式就像教小孩学走路,不直接告诉它正确答案,而是让它自己尝试,根据结果的好坏(比如答案是否正确)来调整自己的行为。这种方法不需要预先标注好的数据,完全靠AI自己摸索,没有输入任何带标记的数据,这也是为什么这个版本的名字带Zero的原因,表示零样本输入。
# 模型开悟时刻
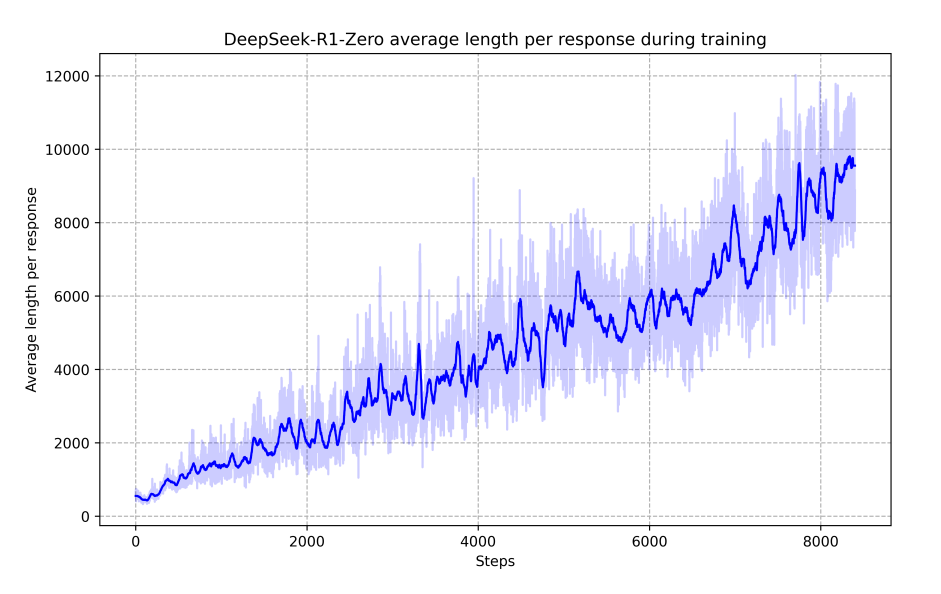
在训练 DeepSeek-R1-Zero 的时候,模型在推理过程中还涌现出一个「aha 时刻」,也就是解决关键一步,恍然大悟的时刻:

模型就好像活了一样,它有像人一样的思想爆发火花,你甚至可以说它的智能自行升级了。并且研究人员发现随着训练步数的增加,模型自动学会了花费更多的时间的时间来进行推理。

也就是说模型自己找到了优化方向:即花费更多时间进行推理,答题的准确率也越高。
# DeepSeek-R1-Zero 缺陷
DeepSeek-R1-Zero 表现非常惊艳,在数学和编程方面的能力已经达到 OpenAI-o1-0912 的水平。但是也有一个明显的缺陷,就是生成的答案可读性差,经常出现中英文混杂。

# DeepSeek-R1
针对 DeepSeek-R1-Zero 的问题,DeepSeek 团队采取了一系列的优化措施。首先,用数千条人工处理的高质量COT数据(比如详细的解题步骤),通过监督微调(SFT)的方式,让它有个“冷启动”,然后再用强化学习进一步训练。这样生成的答案更清晰,语言也更统一。
用更通俗的话来解释就是,研究人员给了DeepSeek-R1-Zero 一些优质例题,教它规范的解题格式,再用强化学习训练。最终它解题又快又准,格式工整。此时得到一个 Checkpoint, 我们姑且把这个Checkpoint 称之为 DeepSeek-R1-One。
然后,再用训练 DeepSeek-R1-Zero 的方式,用 DeepSeek-R1-One 生成一批高质量的 COT Data(长思维链数据),同时再结合knowledge Data(主要是领域数据,以增强AI的写作,角色扮演等其他通用任务方面的能力),以及人类反馈数据等,再以 DeepSeek-V3 为基础模型进行强化学习,这样最终就得到了 DeepSeek-R1。
# 蒸馏模型
在得到 DeepSeek-R1 模型之后,研究团队还进行了第三步的尝试:能否用同样的数据和方法对其他小模型进行微调,从而让小模型也获得较强的推理能力呢? 就好比我们把学霸的学习笔记,解题思路传授给差生,从而让差生也变成学霸。于是他们用 Qwen-2.5 和 llama3 微调出了6个小模型(1.5b,7b,8b,14b,32b,70b)结果发现他们果然表现出优秀的推理能力,在各个方面的评分都大幅度提升。

值得一提的是由于蒸馏的模型是用 COT Data 和 Knowledge Data 直接 SFT 得到的,没有上强化学习,所以你会发现本地部署的 deepseek-r1:7b 之类的模型会时不时出现比如推理过程中英文混合,输出格式混乱的情况。 还有就是,蒸馏模型的推理速度要比满血版的 DeepSeek-R1 慢一些,这是因为 MTP( 多令牌预测)是 DeepSeek-V3 独有的特性,通过一次预测2个Token来提高模型输出速度。而 Qwen2.5 和 llama3 并没有使用这个技术。
# 失败的尝试
在得到蒸馏模型之后,研究团队做了进一步的尝试,那就是如果直接用 Qwen 或者 llama 作为基础模型,采用训练 DeepSeek-R1 模型的方法,是否也能训练出高智商的推理模型呢?尝试的结果是:不行。
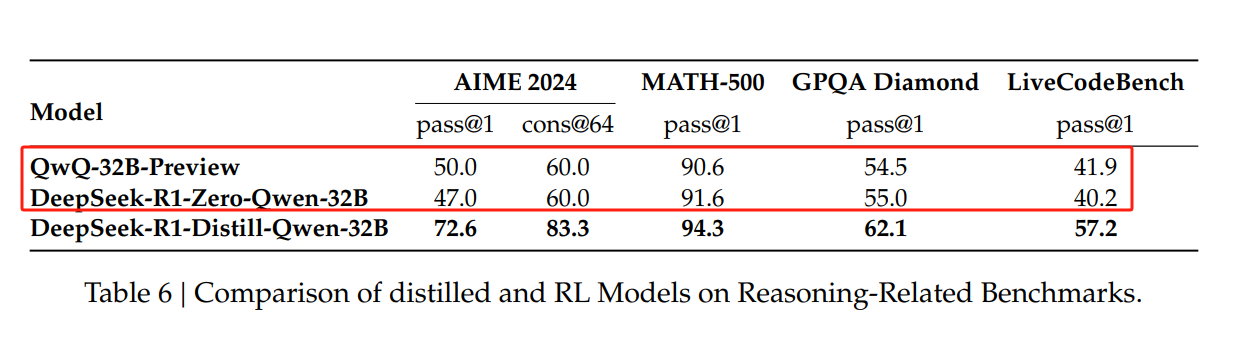
如上图所示,以 Qwen-32B 为基础模型,采用同样方法训练出来的 DeepSeek-R1-Zero-Qwen-32B 各方面的能力并没有什么提升,有的甚至还不如基础模型。跟蒸馏模型那更是没法比。所以说这套训练方法对基础模型是有一定的要求的,也就是说基础模型的“智商”不能太低,就好比你把一个小学生关起让他再怎么自学也做不出大学生的微积分题目。
另一个失败的尝试就是,DeepSeek 团队在训练 DeepSeek-R1 的早期阶段尝试了采用 MCTS 和 PRM 的方法来训练推理模型,结果发现都失败了。当然,研究人员话说的很严谨,他们说:
我们在这里分享我们的失败经历以提供见解,但这并不意味着这些方法无法开发有效的推理模型。

# 总结
从 DeepSeek-R1 的训练过程我们可以简单得出以下三点结论。
- 仅仅依靠纯强化学习(PURE-RL)和简单的奖励机制,就可以训练出强大的推理模型。一个优秀的学生仅仅通过自学就能成为学霸。
- 采用优质的 COT 数据蒸馏小模型,可以大大提升小模型的推理能力。学渣只要学习了学霸的学习笔记,也能变成学霸。
- 小模型自身不能光靠纯强化学习获得强大的推理能力。学渣不能通过自学变成学霸。 事实上 Kimi1.5 采用的训练策略基本跟 DeepSeek 的差不多(有兴趣的可以去阅读本文底部的参考文献 [1]),但是结果确差很远,估计可能就是 Kimi 的基础模型**“智商不够”。**
# 核心技术解读
接下来我们对 DeepSeek-V3 和 DeepSeek-R1 所用到的核心技术进行简单的梳理解读。
# 1. GRPO训练策略
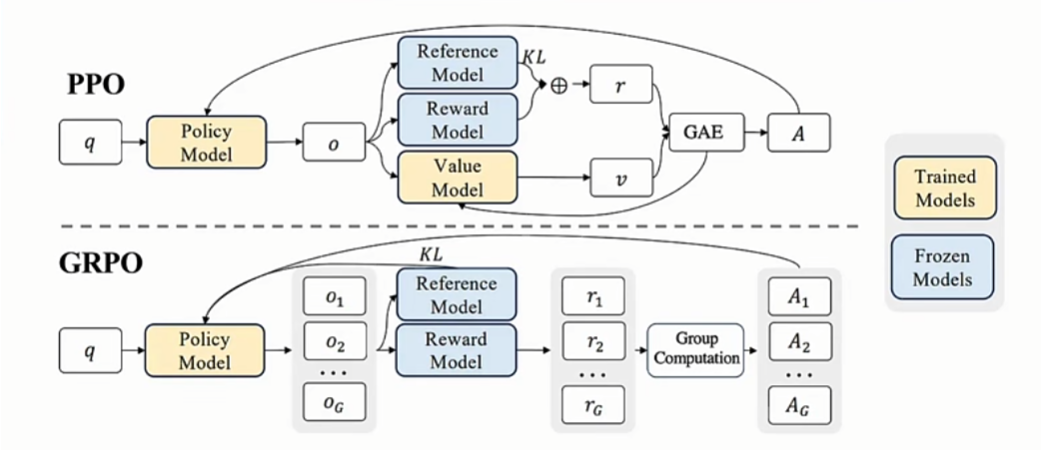
GRPO(Group Relative Policy Optimization,群体相对策略优化)是一种强化学习优化方法,其核心思想是通过组内输出的相对评分替代传统PPO中的价值网络模型(Critic 模型)。传统的 PPO 算法依赖于一个与策略模型大小相当的价值网络来评估优势函数,每完成一步训练都要更新价值网络,计算复杂度高,内存占用大。而GRPO则完全摒弃了Critic模型,采用了更轻量化的实现。
下面举个简单的例子来说明 GPRO 的工作原理。
假设训练一个聊天机器人回答数学问题:
- 生成组内输出:针对问题“1+1=?”,GRPO会生成多个候选答案(如“2”“3”“答案需要更多步骤”)。
- 计算组内奖励:根据规则(如答案正确性)或模型评分,为每个答案赋予奖励(如“2”得高分,“3”得低分)。
- 计算相对优势:基于组内奖励的均值和标准差,计算每个答案的相对优势(例如,正确答案的优势值为正,错误答案为负)。
- 优化策略:通过最大化相对优势的目标函数,调整模型参数,使正确答案的生成概率提升,错误答案降低。
# GRPO vs. PPO 的本质区别
| 区别点 | GRPO | PPO |
|---|---|---|
| Critic模型 | 完全省去Critic模型 | 需要Critic模型估计状态价值函数 |
| 优势计算 | 基于组内输出的奖励相对值(无模型) | 依赖Critic模型预测的绝对价值 |
| 计算复杂度 | 更低(无需训练额外模型) | 更高(需联合优化策略和Critic模型) |
| 适用场景 | 奖励易于定义且组内对比有效的问题 | 需精准价值估计的复杂任务 |
| 稳定性 | 依赖组内样本的多样性 | 通过Critic提供更平滑的价值估计 |
# 关键总结
- GRPO的优势:简化架构、降低计算成本,适合奖励规则明确的任务(如代码生成、数学解题)。
- PPO的优势:通过Critic模型提供更精细的价值估计,适合需要复杂状态评估的场景(如开放域对话)。
两者本质区别在于是否依赖外部价值估计模型,以及优势函数的计算方式。GRPO通过组内对比实现轻量化,而PPO通过Critic模型实现精准优化。
# MLA 架构
Multi-head Latent Attention,多头潜在注意力。是DeepSeek-V3中提出的高效注意力架构,核心目标是通过低秩压缩减少推理时的显存占用(KV缓存),同时保持与传统多头注意力(MHA)相近的性能。 直观解释就是,假设传统多头注意力(MHA)需要为每个头存储完整的键(Key)和值(Value),而MLA通过以下两步优化:
- 低秩压缩:将多头键值压缩为更小的潜在向量(Latent Vector),这里跟 Stable Diffusion 训练的时候会将图片压缩放入潜在空间是一样的原理。
- 解耦查询:将查询(Query)分解为压缩部分和独立的位置感知部分。
假设输入序列长度为 4096,使用MLA后:
- KV缓存: 传统MHA需存储 4096 * 32,768 = 134M 参数。
- MLA缓存: 仅需存储 4096*(512+64) = 4096*576 ≈ 2.36M 参数,显存减少约98%。
# 举例说明
这里我用一个更贴近日常生活的比喻来解释 MLA(多头潜在注意力):
假设你有一个巨大的衣柜(类比模型的显存),里面挂满了各种衣服(类比模型的注意力头存储的键值信息)。传统方法(MHA)需要为每件衣服保留独立的位置信息,而MLA像一种“折叠压缩法”,把衣服分类折叠压缩装进一个个收纳盒,然后给每个收纳盒贴上标签,然后既能节省空间,又让你快速找到需要的衣服。
# MLA的核心思想
- 压缩:把复杂的键值信息“折叠”成精简版本,减少存储量。
- 标记位置:用特殊标签(位置编码)记住信息的位置,确保使用时能快速还原。
- 平衡:牺牲一点点折叠时间(计算开销),换来巨大的空间节省(显存优化)。
# 现实中的MLA应用场景
- 长文本聊天:比如让AI读一本1000页的小说,MLA能避免显存爆炸,流畅生成总结。
- 手机端AI:在内存有限的设备上,MLA让大模型也能运行,比如实时翻译长语音。
# 总结
MLA就像一种“衣柜整理术”,通过折叠和标记,让AI在处理海量信息时既省空间又不手忙脚乱!
# FP8 混合精度训练
传统的模型都是采用 FP32 全精度计算,这样虽然精度高,但是计算量也大很多。DeepSeek-V3 在训练模型时采用了 FP8 混合精度计算。对于矩阵乘法(GEMM)、激活值存储(如隐藏层输出)这些计算就采用低精度(FP8)计算方式,而对于权重更新、归一化(LayerNorm)这些计算则采用全精度(FP32)计算方式。
简单来说,就是使用FP8进行中间结果的计算,而在最终累加时则采用FP32。
# 举例说明
这里以厨师烹饪为例,给 FP8 混合精度提供一个更直白的解释。
厨师在烹饪的过程中需要对每道菜肴的调料进行准控制,传统方法(FP32)要求你用精确到毫克的天平称量所有调料,而FP8混合精度则像一套“智能调料勺”,关键步骤(比如加盐,鸡精这些调料)用非常精确的小勺,其他步骤用不怎么精确的大勺(比如倒油,加水等操作)。
再举一个例子,比如有些商店会在日常记账时为了简化流程而省略了零头,但在月底盘点时,会请专业的财务人员使用计算器将所有细节一一核算清楚。
总而言之,FP8 混合进度训练,它不是无脑压缩,而是“把好钢用在刀刃上”的工程智慧! 让大模型训练既高效又稳定。
# DualPipe跨节点通信
假设你经营一家跨国物流公司(AI训练集群),需要在多个国家的分拣中心(GPU节点)之间高效转运包裹(数据)。传统流水线经常卡在等待包裹中转(通信延迟),而DualPipe像一套“双向传送带+智能调度系统”,让分拣员(GPU)永远不闲着。
传统的训俩方式 GPU 节点之间的通信是单向并且串行的,还是以物流为例包裹只能从一个方向进入分拣中心(例如从中国→德国→美国)。在德国分拣中心处理完之前,美国的分拣中心只能干等着。跨国运输(跨节点通信)时,整个流水线停止,直到包裹到达下一站。分拣员50%时间在等国际快递,效率低下。这使得跨机房、跨数据中心训练时,网络延迟成为主要障碍。
# DualPipe的解决方案
- 双向传送带设计: 中国和美国同时发出包裹,相向而行。德国分拣中心先处理中国来的包裹,接着立刻处理美国来的,气泡减少50% 。
- 跨国运输与分拣重叠: 当中国分拣中心处理完一批包裹时,立即开始打包发往德国,同时处理下一批包裹。通过智能调度系统预判运输时间,确保分拣员永远有活干。
- 多节点协同优化: 根据实时交通(网络带宽),自动选择最快路径(如中国→德国用空运,德国→美国用海运)。
值得一提的是,DeepSeek买到的计算卡,由于受到芯片法案的出口限制,英伟达就不得不在通信任务的处理能力上做了削减。比如,H100阉割成H800后,通信能力大约下降了6成左右,通信延迟增加了2倍。
为了解决这个问题,DeepSeek只能做更底层的优化。原本132个流处理器既可以处理计算任务,也可以处理通信任务,但DeepSeek用PTX语言强制其中32个只能用于处理通信任务。 于是在V3训练的典型负载下,尽管计算单元少了,但通信上的瓶颈一下解放了出来。
总结:DualPipe就像一套“跨国物流AI调度系统”,通过 双向流水线+实时通信优化,让全球GPU像本地设备一样协同工作。它不是在消除距离,而是让距离变得“透明”!
# MTP 技术
Multi-Token Prediction,多令牌预测,这是 DeepSeek-V3 中采用的新技术,简单来说,原来大模型每次都是预测一个 Token,而 DeepSeek-V3 采用的是一次预测 2 个 Token,这也是为什么 DeepSeek-R1 响应输出的速度会这么快。
这个创新的核心是,怎么添加一个额外的小型transformer层,用来生成第二个token,怎么设计双重的损失函数。 这也是为什么 Deepseek 最终采用的方案是一次预测 2 个 Token 而不是 200 个,因为后续 Token 预测的准确率会急剧下降。 根据 DeepSeek-V3 的技术论文可以得知,预测第二个 Token 的时候接受率在 85%-90% 之间,能使的推理的速度提升 1.8 倍,消耗资源只增加了 5%。

若一次预测5个Token,接受率骤降至30%以下,导致净加速比反而不如预测2个Token。而且此时那个小 transformer 层消耗的显存也会大幅增加,甚至可能超过主模本身,那就有点得不偿失了。
另外,多Token预测需要平衡不同位置的损失权重。预测2个Token时,可通过简单加权实现稳定训练;预测100个Token时,损失函数易陷入局部最优,导致模型发散。
# 总结
DeepSeek-V3选择预测2个Token,是在速度、精度、复杂度、稳定性之间找到的最优解。它通过:
- 精准预测:高接受率确保候选Token有效;
- 轻量扩展:最小化额外计算与显存开销;
- 端到端优化:匹配硬件限制与用户体验需求。
这一决策体现了AI工程中“用20%的复杂度解决80%的问题”的核心哲学,而非盲目追求理论上的极致速度。
# 参考文献
- https://x.com/kimi_moonshot/status/1882413059513471044?5=46&t=2QnaL4UHDCHYOWAWNe4NCW
- https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
- https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
- https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
本站博文如非注明转载则均属作者原创文章,引用或转载无需申请版权或者注明出处,如需联系作者请加微信: geekmaster01