Lotus 源码研究 05 - PC1 SDR 多核加速优化实现
尼采
生命中最艰难的阶段不是没有人懂你,而是你自己不懂你自己。
转载声明
本文转载自原语云公众号 Lotus PC1多核计算的L3缓存加速的实现分析和优化 (opens new window)。欢迎订阅,第一时间获取技术干货。
本文属于原语云的计算加速系列,这篇将重点介绍原语云的 PC1 的 CPU L3 计算核组自定义绑定的设计和实现。
# 1. 关于 CPU 缓存
目前的计算机体系程序计算的中间数据都是存储在 RAM 设备里面,也就是我们通常说的内存中,例如一个运行的程序中的常量,变量,函数等编译的二进制或者字节码等都是存储在内存中。 当 CPU 需要读取某个数据的时候,先从 CPU 的缓存中查找,如果找到了就立即读取发送给 CPU,否则就会从相对速度比较慢的内存中去读取。 CPU 对内存的读取是以块为单位,也就是说 CPU 一次会读取这个内存地址所在的整个内存块的数据,后续的计算中对这块内存任何数据的访问都可以直接在 CPU 缓存中读取。 这种读取机制会让 CPU 命中 cache 的概率非常高,大多数 CPU 可以在缓存中找到90%的数据,也就是只有10%的读取会穿透缓存,需要访问内存,这种机制会极大的减少对内存的访问,从而加速计算的读取。
比较新的CPU都有四级缓存,一级/二级/三级/四级,通常称为:L1d/L1i/L2/L3 缓存,读取数据的时候也是依照上面的顺序依次检测,找到了就立即读取发送给CPU,没找到就穿透到下一级缓存。 缓存空间一般也是逐步增大,2012 年前的 CPU 的 L3 缓存都是外置芯片,2012 年才内置到CPU中,也正是 L3 缓存的出现让 CPU 对内存的访问降低到了5%,95%的访问都可以命中 CPU 缓存, 例如 AMD 5900X 的第一个核的缓存空间分配情况如下:
{
"l0_size": 32768,
"l1_size": 32768,
"l1_id": 0,
"core": 0,
"l2_id": 0,
"online": 1,
"l3_size": 33554432,
"l3_id": 0,
"l2_size": 524288,
"l0_id": 0
}
下面我们通过一个简单的二维数组遍历的例子来验证下 CPU 缓存对数据访问的加速效果:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
int main(int argc, char *argv[])
{
int i, j, t, r;
clock_t s,e;
char *v, key[64] = {'\0'}, val[255] = {'\0'};
// 1, parse the rows arguments and default it to 10240
r = 10240;
for (i = 0; i < argc; i++) {
v = argv[i];
if (strlen(v) > 2 && strncmp(v, "--", 2) == 0 && strchr(v, '=') != NULL) {
j = sscanf(v, "--%63[^=]=%254s", key, val);
if (j != 2) {
printf("Invalid arguments pair: %s", v);
return 1;
}
if (strcmp(key, "rows") == 0) {
r = atoi(val);
}
}
}
// 2, do the memory alloc
int **arr = (int **) calloc(r, sizeof(int *));
if (arr == NULL) {
printf("Failed to alloc\n");
return 1;
}
// 3, initialize the array
for (i = 0; i < r; i++) {
arr[i] = (int *) calloc(r, sizeof(int));
if (arr[i] == NULL) {
printf("Failed to alloc col %d\n", i);
return 1;
}
for (j = 0; j < r; j++) {
arr[i][j] = j;
}
}
// 4, Sequential access
s = clock();
for (i = 0; i < r; i++) {
for (j = 0; j < r; j++) {
// printf("arr[%d][%d]=%d\n", i, j, arr[i][j]);
t = arr[i][j];
}
}
e = clock();
printf("Done, t=%d, cost: %.3f secs\n", t, (double)(e-s)/CLOCKS_PER_SEC);
// 5, Jump access
s = clock();
for (j = 0; j < r; j++) {
for (i = 0; i < r; i++) {
// printf("arr[%d][%d]=%d\n", i, j, arr[i][j]);
t = arr[i][j];
}
}
e = clock();
printf("Done, t=%d, cost: %.3f secs\n", t, (double)(e-s)/CLOCKS_PER_SEC);
return 0;
}
拷贝上述代码到 loop.c 文件中,然后编译,运行:
gcc -g -Wall ./loop.c
/a.out --rows=10240
上述 C 程序定义了一个int型的二维数组,依据 rows 参数动态申请内存进行初始化,之后依次通过顺序循环和跳跃循环来遍历访问二维数组,再记载打印两个循环的耗时,实验数据如下:
// 数组长度 1024 个整数
➜ ~ ./a.out --rows=1024
Done, t=1023, cost: 0.002 secs
Done, t=1023, cost: 0.003 secs
// 数组长度 10240 个整数
➜ ~ ./a.out --rows=10240
Done, t=10239, cost: 0.093 secs
Done, t=10239, cost: 0.453 secs
// 数组长度 20480 个整数
➜ ~ ./a.out --rows=20480
Done, t=20479, cost: 0.379 secs
Done, t=20479, cost: 1.855 secs
上述数据显示随着二维数组的长度的不断增大,两种操作的耗时差越大,这种耗时差距的本质就是 CPU 缓存的命中率的不同导致的。 第一种循环的大部分数据访问的内存寻址都是集中的,也就是在连续的内存块上,CPU 的块内存读取方式会让这种数据访问极大命中缓存, 而第二种访问方式内存寻址跳跃性很大,导致 CPU 缓存命中率降低了很多,而且 rows 越大这两个时间差距越大,rows 到了比较大的值。例如 r=102400 时,第二个跳跃性的访问过程可能需要等上几分钟。
# 2. PC1计算的SDR多核加速
最早太空竞赛的时候默认的 Lotus 代码没有多核计算加速,那会类似 7F32 这种主频很高,但是核数少的 AMD CPU 对于 PC1 计算确实有投入产出的优势。 当官方实现了 SDR 的多核加速之后,给了计算频率虽然低但是核数多的 CPU(如7742,7542) 发挥空间,毕竟芯片的发展之路也是由原来的更快演变成了并行的方案了。
# SDR 多核加速原理:
- 首先,多个线程用 parent node 里面的的数据预先填充 buffer, 并完成部分 sha2.compress256 hash 计算,主要实现代码在 multi.create_label_runner 函数中。
- 然后,在 multi.create_layer_labels 函数的主线程空间里面 进行主要的 sha2.compress256 hash 计算。
- 最后,在 multi.create_label_encoding 里面的主线程把计算后的数据写入到磁盘。
回到上述讲到的 CPU 缓存加速的效果,如果这些计算线程都集中在共享 CPU 缓存的核心上面,整个计算过程会极大的命中数据读取缓存, 从而加速整个计算过程, 当然缓存空间最大的是 L3 缓存,通常我们也以 L3 缓存的共享核心作为一组来分别绑定到不同的计算线程。
你可以通过导出如下环境变量来启用 SDR 多核加速:
export FIL_PROOFS_USE_MULTICORE_SDR=1
同时,你可以通过如下环境变量来设置生成 label 的并行数,也就是上述加速原理第一步中的加速的线程数:
export FIL_PROOFS_MULTICORE_SDR_PRODUCERS=3
注意:
经常有人在这里踩坑,SDR_PRODUCERS 默认值是3,官方也解释过了这个值是在 AMD 3970x CPU上实践过的最优值,很多工程师直接就用的这个值来跑全部的芯片, 这肯定会导致问题的,例如:7302/7402这种芯片的 SDR_PRODUCERS 设置为3会导致 PC1 计算偏慢很多,甚至跑到十几个小时,错误的配置可能会导致计算速率还不如单核计算来的快。
怎么确定 SDR_PRODUCERS 的值呢?
这个值等于 CPU 共享某组 L3 缓存的核心数减去一,例如: AMD 5900x 上共享第一组L3缓存的 CPU Processor 如下:
lscpu -e | grep ":0 "
## 输出内容
0 0 0 0 0:0:0:0 yes 4950.1948 2200.0000
1 0 0 1 1:1:1:0 yes 4950.1948 2200.0000
2 0 0 2 2:2:2:0 yes 4950.1948 2200.0000
3 0 0 3 3:3:3:0 yes 4950.1948 2200.0000
4 0 0 4 4:4:4:0 yes 4950.1948 2200.0000
5 0 0 5 5:5:5:0 yes 4950.1948 2200.0000
12 0 0 0 0:0:0:0 yes 4950.1948 2200.0000
13 0 0 1 1:1:1:0 yes 4950.1948 2200.0000
14 0 0 2 2:2:2:0 yes 4950.1948 2200.0000
15 0 0 3 3:3:3:0 yes 4950.1948 2200.0000
16 0 0 4 4:4:4:0 yes 4950.1948 2200.0000
17 0 0 5 5:5:5:0 yes 4950.1948 2200.0000
可以看到,一共有 12 个 Processor 共享一组 L3 缓存,但是由于我开启了超线程,所以实际上是有 6 个核心共享第一组 L3 缓存。
所以此时你可以把 SDR_PRODUCERS 设置为 6-1=5,另外一个核心分配给主线程,通常我们建议这个值不超过3,因为过多反而会变慢。
原语云管理终端是会自动的通过一个叫做 auto_lotus_sdr_producers 的 ark 底层函数进行计算,lotus-p1-worker 应用保持默认配置就好,最大也是默认设置的不超过3:
# 3. PC1 L3 核心分组和绑定
首先我们要明确的一件事情是:计算线程和指定 Processor 的绑定本身是通过 Linux 内核提供的设置进程和线程的 CPU 亲和力 (CPU affinity) 的接口来实现的, 将特定的进程调度到指定的 CPU Processor 集合上去运行,这是系统内核的工作,并不是 lotus 做的事情。
Lotus 默认的 CPU L3 分组以及 SDR 线程绑定的实现如下:
# 3.1 初始化 CPU 加速核组
vanilla.cores.rs 里面有一块 lazy_static 的代码,会调用一个函数把全部的 core (不是Processor) 按照 L3 共享来分类,得到一个分组的集合,后续计算会直接从这个缓存的vec集合中获取核组信息,核心代码如下(注意看代码注释):
// 通过hwloc获取 core的depth
let core_depth = match topo.depth_or_below_for_type(&ObjectType::Core) {
Ok(depth) => depth,
Err(_) => return None,
};
// 获取全部的 Core (物理核,不包括超线程出来的 Processor )
let all_cores = topo
.objects_with_type(&ObjectType::Core)
.expect("objects_with_type failed");
let core_count = all_cores.len();
let mut cache_depth = core_depth;
let mut cache_count = 1;
// 通过 core_depth 来计算 cache_count
// cache_count 表示 CPU 一起多少个 Core深度的 Cache 个数
// 这里得到的就是 CPU 的 L3 缓存个数
while cache_depth > 0 {
let objs = topo.objects_at_depth(cache_depth);
let obj_count = objs.len();
if obj_count < core_count {
cache_count = obj_count;
break;
}
cache_depth -= 1;
}
// 得到最终的分组数量和每组的核心数
// 全部核数除以 L3 缓存个数 = 缓存组数
let mut group_size = core_count / cache_count;
let mut group_count = cache_count;
info!("core_depth: {:?}, core_count: {:?}, group_size: {:?}, group_count: {:?}",
core_depth, core_count, group_size, group_count);
例如在我的 AMD 5900X 的机器上运行上述逻辑的输出如下:
core_depth: 3, core_count: 12, group_size: 6, group_count: 2
5900X 是12 核 24 线程的,结合上述代码理解如下:
一共有12个core,即 core_count=12,得到的 cache_count = 2,也就是5900X CPU 只有两个 L3 缓存
故 group_size = core_count / cache_count = 6
进而得到,group_count = cache_count = 2
这个分组会缓存到一个叫做 CORE_GROUPS 的静态集合里面,以 AMD 7542 为例,这款 CPU 有 8 个缓存对象 (cache_count),每 4 (group_size) 个核共享一组 L3 缓存,初始化后,CORE_GROUPS 的空间结构如下:
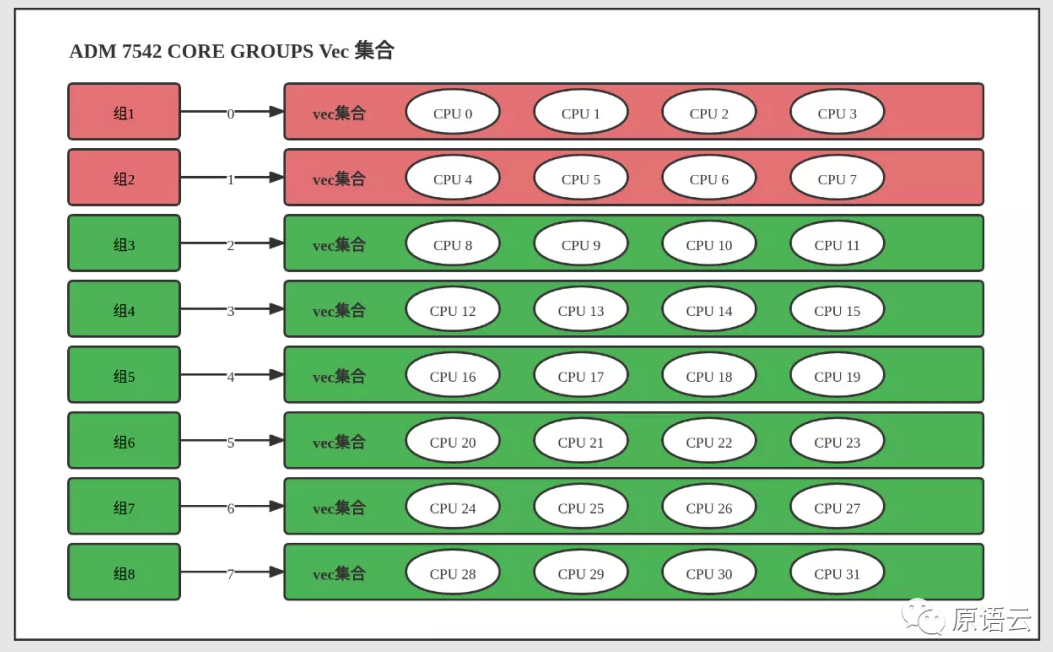
# 3.2 核心的选择和绑定
例如我们在 7542 的CPU上通常会用1T内存并行 14 PC1 计算,rust层是通过调用一个 checkout_core_group 的函数来选择一个核组,接下来的 PC1 计算线程只会绑定到这个这个选定的核组中的 cpu cores。
核组的选择逻辑:
遍历上一步提到的
CORE_GROUPS静态全局变量,找到第一组没有被互斥锁锁定的核组 (group.try_lock成功),找到了就返回并且把这一组核心锁定,核心代码实现如下:match &*CORE_GROUPS { Some(groups) => { for (i, group) in groups.iter().enumerate() { // info!("{}: {:?}", i, group); match group.try_lock() { Ok(guard) => { info!("checked out core group {}", i); return Some(guard); } Err(_) => debug!("core group {} locked, could not checkout", i), } } None } None => None, }核心的绑定逻辑:
checkout 得到的核组,会伴随整个 PC1 的
labels encoding计算过程,具体绑定逻辑是:这个核组的第一个核心绑定到主计算线程上面,剩下的核心依次绑定给labels_runner线程 (SDR_PRODUCERS定义的数量), 绑定的具体实现是通通过一个叫做bind_core的函数,本质上是线程 CPU 亲和力的系统调用。计算过程结束后,锁定的核组会被释放,供给下一个任务计算需要,核心代码如下(注意看代码):// 主线程绑定 let _cleanup_handle = (*core_group).as_ref().map(|group| { // This could fail, but we will ignore the error if so. // It will be logged as a warning by `bind_core`. info!("binding core in main thread"); group.get(0).map(|core_index| bind_core(*core_index)) }); // label runner 线程绑定 // 下面的变量 i 为 producer的序号 <= SDR_PRODUCERS 数 // 不同的 producer 绑定到不同的核心进行计算 let core_index = if let Some(cg) = &*core_group { cg.get(i + 1) } else { None }; runners.push(s.spawn(move |_| { // This could fail, but we will ignore the error if so. // It will be logged as a warning by `bind_core`. info!("binding core in producer thread {}", i); // When `_cleanup_handle` is dropped, the previous binding of thread will be restored. let _cleanup_handle = core_index.map(|c| bind_core(*c)); create_label_runner(...) }));
# 4. 原语云核心分组的优化
了解了上述L3分组和绑定的实现后,回到一个现实骨感的问题,例如,AMD 7542 的芯片,我们通常会在1T的内存机器上并行至少14个 PC1 计算,但是如上图描述的7542的机器只有8组加速核心, 也就是前面的8个扇区计算都可以单独绑定核组计算,但是后面的 6 个并行计算没办法绑定会怎么样呢?
如果 PC1 worker 进程没有设置 CPU 的亲和力,那么剩下的没有绑定核组的6个 PC1 并行就会使用全部的 CPU。
如果 PC1 worker 进程设置了CPU亲和力,那么剩下的6个计算都会集中在这些设置的核心上运行。
无论是上述任何一种方式都无疑会干扰前面绑定了核组的计算的CPU 缓存命中率导致计算效率不可控制的下降,自然计算时间会拉长并且不稳定。 为了解决这个问题,提高PC1计算的速度和稳定性(这两者通常共存),我们需要重新设计这个核组的分配,然后让计算的CPU资源完全按照我们的规划来分配,思路是考虑一组共享L3的加速核心并行两个任务,也就是8组核心可以并行16个任务, 通常情况下我们会拿出7组核心用于并行14个PC1任务,剩下的一组核心单独绑定进行PC2计算,有如下两种方式:
每个核组的核心数不变,把核心的超线程额外加分一组:
默认 CPU 是打开超线程的,AMD 7542 有32核64线程,也就是我们可以把例如,CPU 0,1,2,3对应的超线程 15,16,17,18也分一组,虽然是同一组 core,但是超线程本身也有一定的加速效果, 主要是这样CPU的资源分配不会乱窜,这样可以得到16组加速核心。
每个核组的核心减半,PC1 的 SDR 并行核心数减少:
如果机器关闭了超线程或者不想使用超线程,也可以把分组的核心数减半,例如:7542每组加速核心有4个 core,可以分成两组2个 core 的,再设置
SDR_PRODUCERS=1绑定给两个 PC1 并行计算, 这样做到用主 core 在一组L3缓存上并行两个计算,也可以保证CPU的资源分配的有序不乱,超线程可以用于单独的 PC1 进程或者 PC2 进程的计算。
无论是上述哪种思路,都需要修改核组的初始化代码,还需要修改 bind_core 函数允许绑定任意的 Processor (例如超线程) 而不是只能是 core,原语云并并没有把这些拆分逻辑写到rust层,
而是通过引入一个叫做 FIL_PROOFS_SDR_CACHE_GROUPS 的环境变量允许外部完全自定义核组的分配,核心代码如下(注意看注释):
// 自定义核组的解析
let group_list: Vec<&str> = sdr_groups.as_str().split("/").collect();
for g in group_list {
let mut cpu_set: Vec<CoreIndex> = vec![];
let cpu_list: Vec<&str> = g.split(",").collect();
for core in cpu_list {
cpu_set.push(CoreIndex(core.parse::<usize>().unwrap()));
}
// push the current cpu set to the global groups
core_groups.push(cpu_set);
}
info!("core_groups: {:?}", core_groups);
// bind_core的修改
// 允许绑定 Processor
let bind_to = hwloc::CpuSet::from(core_index.0 as u32);
// Thread binding before explicit set.
let before = locked_topo.get_cpubind_for_thread(tid, CPUBIND_THREAD);
info!("core_index: {:?}, binding to {:?}", core_index, bind_to);
例如:我们把 7542 的核心通过逗号隔开,不同的核组通过/隔开传递给到 rust 去初始化全局的 CORE_GROUPS ,这样可以完全在外面控制 PC1 任务的核心绑定。
在原语云中这个核心的分配也是通过一个叫 auto_cpu_l3_share_cores 的 ark 底层函数自动实现的(有兴趣的可以参考原语云的使用文档 (opens new window)):
默认的7542的核心分组如下:
root@worker01:~# qark-client --rsc cpu.l3_cache_cores
[
[0,1,2,3,32,33,34,35], // 第 1 组核心
[4,5,6,7,36,37,38,39], // 第 2 组核心
[8,9,10,11,40,41,42,43],
[12,13,14,15,44,45,46,47],
[16,17,18,19,48,49,50,51],
[20,21,22,23,52,53,54,55],
[24,25,26,27,56,57,58,59],
[28,29,30,31,60,61,62,63] // 第 8 组核心
]
除非 7h12 这类本身就带 16 组 L3 缓存的,否则类似 7542 这种芯片 L3 缓存组数不够 12 组的话,原语云默认会对核组进行二次拆分,也就是把超线程也作为一组,得到 16 组加速核心,拆开分组后如下:
root@worker01:~# qark-client --rsc cpu.l3_cache_cores --part=2
[
[0,1,2,3], // 第 1 组核心
[4,5,6,7], // 第 2 组核心
[8,9,10,11],
[12,13,14,15],
[16,17,18,19],
[20,21,22,23],
[24,25,26,27],
[28,29,30,31],
[32,33,34,35],
[36,37,38,39],
[40,41,42,43],
[44,45,46,47],
[48,49,50,51],
[52,53,54,55],
[56,57,58,59],
[60,61,62,63] // 第 16 组核心
]
# 5. 测试优化结果
通过这种方式会把7542的全部的 Processor 都用满,每台 worker 并行14个PC1 计算可以稳定每天完成 2.7T 左右的 PC1/PC2 计算,htop 截图如下:
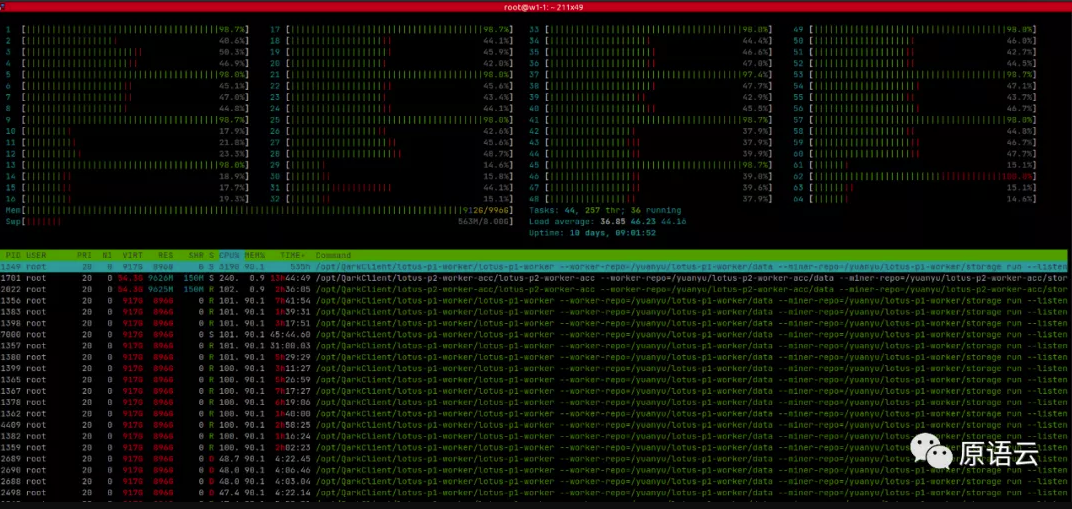
Tips:
近期原语云将在深圳的办公室举行 lotus 技术线下交流,探讨和分享 lotus PC1/PC2/C2 计算加速的优化和思考,欢迎有兴趣的小伙伴公众号留言或者加本人微信报名,仅限 8 个人参与。
本文首发于【原语云】公微信服务号。原语云是专注智能运维的SaaS云平台。提供海量服务器的可视化智能运维、Filecoin的集群方案/代码优化/可视化管理/应用生态等一站式云解决方案!
本站博文如非注明转载则均属作者原创文章,引用或转载无需申请版权或者注明出处,如需联系作者请加微信: geekmaster01