Ceph-08 配置 Ceph SSD 缓存池
岸见一郎 -- 被讨厌的勇气
这个世界世界给了你什么,那是你决定不了的。但是怎么看待,怎么利用你手里的东西,确是你可以决定的。
本文介绍如何给 Ceph 存储池配置 SSD 缓存池。
# 1. 缓存池工作原理
Ceph 从 Firefly 版本开始就支持缓存分层特性,所谓的缓存分层其实就是在更快的磁盘(通常是 ssd 或者 NVME)上创建一个存储池,然后将这个存储池放置在
常规复制池或者纠删码存储池的前端去充当缓存,被充当缓存的这个存储池也叫做 Cache Pool,大概工作流程如下如所示:
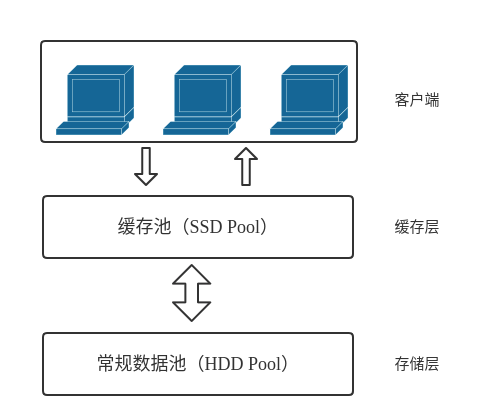
这样设计以后大部分的客户端的 IO 操作都首先通过缓存池来处理,之后再有缓存池将数据回写到后端真正存储数据的数据存储池,由于缓存池一般都是建立在读写速度更快的 SSD 甚至 NVME 磁盘上, 所以客户端将I/O请求提交至缓存池,不管是读还是写操作,它的请求都能立即获得响应,使得客户端能够获得更好的存储体验。
一段时间后(或者当缓存空间不够的时候,这个策略你可以自己配置),缓存层将所有数据再写回后端的存储池。
需要特别说明的是,Ceph 缓存池的设计跟数据池是完全解藕的形式,在缓存层和数据层之间的数据迁移都是自动触发且对客户端透明的。正如官方文档里所说的:
我们应该能够创建缓存池并将其添加到现有数据池中,然后在不中断服务或迁移数据的情况下将其删除。
# 2. 缓存层的工作模式
Ceph 缓存池主要有以下两种工作模式:
1.WRITEBACK:回写模式,也是 Ceph 缓冲池的默认工作模式,此时它的读写过程如下:
写入数据: 客户端将数据写入缓存池,然后会立即收到写入确认。缓存池会根据你配置的策略(比如每隔半小时),将数据回写到真实存储数据的后端存储池。并最终由缓存代理将其从缓存层中删除。
读取数据: 处理来自客户端的读操作时,首先由缓存分层代理将数据从存储层迁移至缓存层,然后再将其返回给客户端。只到数据变得不再活跃或者成为冷数据时,再将其从缓存池中删除。
2.READ-ONLY POOL:它只适用于处理客户端的读操作(弱一致性)。客户端的写操作不涉及缓存分层,所有的客户端写都在存储层上完成。
写入数据: 不缓存,直接写入后端的数据存储池。
读取数据: 如果缓存池中有命中缓存,则直接返回数据,否则缓存分层代理将请求的数据从后端存储层复制到缓存层,再返回给客户端。 然后缓存池会基于你配置的策略,将不活跃的对象从缓存池中删除。这种方法非常适合多个客户端需要大量读取某个文件的场景。 如果你对 Filecoin 挖矿比较熟悉的话,那么你立马就会发现这种模式最适合存储复制证明和时空证明的参数了,一次写入,然后大量的 worker 需要并发读取,完全吻合需求。
# 3. 环境说明
- 操作系统: Ubuntu 18.04 LTS
- Ceph 版本: 12.2.12 Luminous (stable)
- 节点架构: 3 mon(ceph1,ceph2,ceph3), 3 mgr(ceph1,ceph1,ceph2,ceph3) 3 osd(ceph1, ceph2, ceph3)
# 4. 配置 crush class
如果你已经做好 OSD 磁盘分组了,请跳过这一步。
如果没有,那么接下来你可能会问,缓存池是创建在 SSD 磁盘上的,那我如何在指定的 OSD(ssd 磁盘)上去创建存储池呢?
这个问题问得好,首先我们得给磁盘,也就是 OSD 分组。
ceph 从 LUMINOUS 版本开始新增了个功能叫 crush class,又被称之为磁盘智能分组。因为这个功能就是根据磁盘类型自动进行属性关联,然后进行分类减少了很多的人为操作。
在这个功能之前,如果我们需要对 ssd 和 hdd 进行分组的时候,需要大量的修改 crushmap,然后绑定不同的存储池到不同的crush树上面,而这个功能让我们简化了这种逻辑。
ceph中的每个设备都可以选择一个class类型与之关联,通常有三种class类型:
- hdd
- ssd
- nvme
# 4.1 启用 ssd class
默认情况下,我们所有的 osd crush class 类型都是 hdd。

你也可以使用下面的命令来列出当前集群中所有启用的 osd crush class
root@ceph1:~# ceph osd crush class ls
[
"hdd"
]
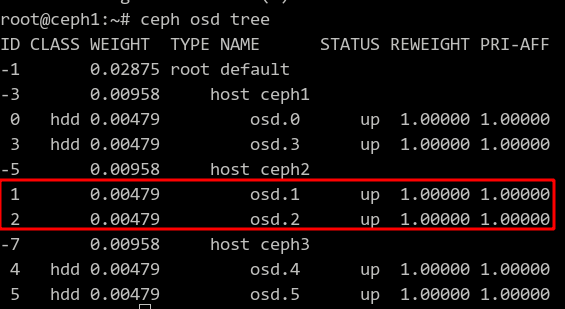
现在我们的需求是:把一些 OSD(如 osd.1,osd.2) 移动到 ssd class 中去,很简单,分两步操作就好了。
(1). 将所有的 ssd 的 osd 从 hdd class 中删除
for i in 1 2;
do
ceph osd crush rm-device-class osd.$i;
done
这个时候,如果我们再次使用 ceph osd tree 查看 osd 布局,会看到被我们指定的 osd 前面不再有 hdd 标识,事实上啥也没有了。
(2). 将刚刚删除的 osd 添加到 ssd class:
for i in 1 2;
do
ceph osd crush set-device-class ssd osd.$i;
done
此时,我们会发现 osd.1 osd.2 已经加入到 ssd class 了

然后我们再次查看 crush class,也多出了一个名为 ssd 的 class:
ceph osd crush class ls
[
"hdd",
"ssd"
]
# 4.2 创建基于 ssd 的 class rule
创建一个 class rule,取名为 ssd_rule,使用 ssd 的 osd:
ceph osd crush rule create-replicated ssd_rule default host ssd
查看集群rule:
ceph osd crush rule list
replicated_rule
ssd_rule
# 配置缓存池
我们先创建一个常规存储池 data
ceph osd pool create data 64 64
# 5.1 创建一个缓存池
我们在步骤 4 中已经创建了一个基于 ssd 的 crush_rule,我们创建一个存储池,使用该crush rule即可。
ceph osd pool create cache 64 64 ssd_rule
你也可以选择把一个已经创建好的存储池迁移到 ssd osd 上:
ceph osd pool get cache crush_rule
验证迁移是否成功:
root@ceph1:~# ceph osd pool get cache crush_rule
crush_rule: ssd_rule
# 5.2 设置缓存层
WRITEBACK 缓存池配置:
# 将 cache pool 放置到 data pool 前端
ceph osd tier add data cache
# 设置缓存模式为 writeback
ceph osd tier cache-mode cache writeback
# 将所有客户端请求从标准池引导至缓存池
ceph osd tier set-overlay data cache
READ-ONLY 缓存池配置
# 将 cache pool 放置到 data pool 前端
ceph osd tier add data cache
# 设置缓存模式为 readonly
ceph osd tier cache-mode cache readonly
通过下面的命令可以查到 data pool 和 cache pool 的详细信息
root@ceph1:~# ceph osd dump |egrep 'data|cache'
pool 1 'data' replicated size 2 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 40 lfor 39/39 flags hashpspool tiers 2 read_tier 2 write_tier 2 stripe_width 0
pool 2 'cache' replicated size 2 min_size 2 crush_rule 1 object_hash rjenkins pg_num 64 pgp_num 64 last_change 42 lfor 39/39 flags hashpspool,incomplete_clones tier_of 1 cache_mode writeback stripe_width 0
对缓存池做一些基本的配置:
ceph osd pool set cache hit_set_type bloom
ceph osd pool set cache hit_set_count 1
ceph osd pool set cache hit_set_period 3600 # 1 hour
ceph osd pool set cache target_max_bytes 1000000000000 # 1 TB
ceph osd pool set cache target_max_objects 10000000
ceph osd pool set cache min_read_recency_for_promote 1
ceph osd pool set cache min_write_recency_for_promote 1
# 5.3 删除writeback缓存池:
由于回写缓存可能具有修改的数据,所以必须采取措施以确保在禁用和删除缓存前,不丢失缓存中对象的最近的任何更改。
(1). 将缓存模式更改为转发,以便新的和修改的对象刷新至后端存储池:
ceph osd tier cache-mode cache forward --yes-i-really-mean-it
(2). 查看缓存池以确保所有的对象都被刷新(这可能需要点时间):
rados -p cache ls
(3). 如果缓存池中仍然有对象,也可以手动刷新:
rados -p cache cache-flush-evict-all
(4). 删除覆盖层,以使客户端不再将流量引导至缓存:
ceph osd tier remove-overlay data
(5). 解除存储池与缓存池的绑定:
ceph osd tier remove data cache
# 5.4 缓存池的相关参数配置
(1). 命中集合过滤器,默认为 Bloom 过滤器,这种一种非常高效的过滤器(看官方文档的意思,好像目前只支持这一种filter):
ceph osd pool set cache hit_set_type bloom
ceph osd pool set cache hit_set_count 1
# 设置 Bloom 过滤器的误报率
ceph osd pool set cache hit_set_fpp 0.15
# 设置缓存有效期,单位:秒
ceph osd pool set cache hit_set_period 3600 # 1 hour
(2). 设置当缓存池中的数据达到多少个字节或者多少个对象时,缓存分层代理就开始从缓存池刷新对象至后端存储池并驱逐:
# 当缓存池中的数据量达到1TB时开始刷盘并驱逐
ceph osd pool set cache target_max_bytes 1099511627776
# 当缓存池中的对象个数达到100万时开始刷盘并驱逐
ceph osd pool set cache target_max_objects 10000000
(3). 定义缓存层将对象刷至存储层或者驱逐的时间:
ceph osd pool set cache cache_min_flush_age 600
ceph osd pool set cache cache_min_evict_age 600
(4). 定义当缓存池中的脏对象(被修改过的对象)占比达到多少(百分比)时,缓存分层代理开始将object从缓存层刷至存储层:
ceph osd pool set cache cache_target_dirty_ratio 0.4
(5). 当缓存池的饱和度达到指定的值,缓存分层代理将驱逐对象以维护可用容量,此时会将未修改的(干净的)对象刷盘:
ceph osd pool set cache cache_target_full_ratio 0.8
(6). 设置在处理读写操作时候,检查多少个 HitSet,检查结果将用于决定是否异步地提升对象(即把对象从冷数据升级为热数据,放入快取池)。它的取值应该在 0 和 hit_set_count 之间,
如果设置为 0 ,则所有的对象在读取或者写入后,将会立即提升对象;如果设置为 1 ,就只检查当前 HitSet ,如果此对象在当前 HitSet 里就提升它,否则就不提升。
设置为其它值时,就要挨个检查此数量的历史 HitSet ,如果此对象出现在 min_read_recency_for_promote 个 HitSet 里的任意一个,那就提升它。
ceph osd pool set cache min_read_recency_for_promote 1
ceph osd pool set cache min_write_recency_for_promote 1
# 参考链接
本站博文如非注明转载则均属作者原创文章,引用或转载无需申请版权或者注明出处,如需联系作者请加微信: geekmaster01